书接上文RDMA简介, 看看 CPU、网卡和 PCIe fabric 是怎么配合实现消息传递的。
背景知识 🔗
Verbs API - slow & fast 🔗
Verbs API 有两类:
- 初始化和配置等低频操作相对比较慢,需要进入内核态执行。比如:
ibv_open_device,ibv_alloc_pd等等; - 数据传输等高频操作则是旁路内核。比如:
ibv_post_send,ibv_poll_cq等等。
这里的“慢”,是指需要进入内核态,因此有相对高昂的上下文切换开销;而所谓 “快”,是指不需要经过内核,没有切换开销。
PCIe terminologies 🔗
网卡通过 PCIe 插槽接入计算机系统。在 PCIe fabric 的拓扑结构中,网卡是一个 PCIe Endpoint. PCIe 协议是个分层协议,从上到下分别是事务层、数据链接层和物理层。
在事务层中传输的数据叫做 TLP (Transaction Layer Packets), 以读写划分可得:MemoryWrite (MWr), 以及 Memory Read (MRd). PCIe 事务还可以进一步划分为三类:
- posted transaction, MWr 就是一个例子,它不需要等待回复;
- non-posted transaction, MRd 就是一个例子,它会触发一个包含读取结果的 completion transaction (记为 CplD);
- completion transation, 由目标发起,用来通知数据可用。
在数据链路层中传输的数据叫做 DLLP (Data Link Layer Packets). 这一层通过 ACK/NACK 来通知数据是否传输成功,是否需要重传等等。其中,Ack 表示成功; NAck 表示失败。
RDMA 传输 🔗
假定通信的双方已经建立 RDMA 连接。以发送数据为例,从程序员的视角,该过程包含以下步骤:
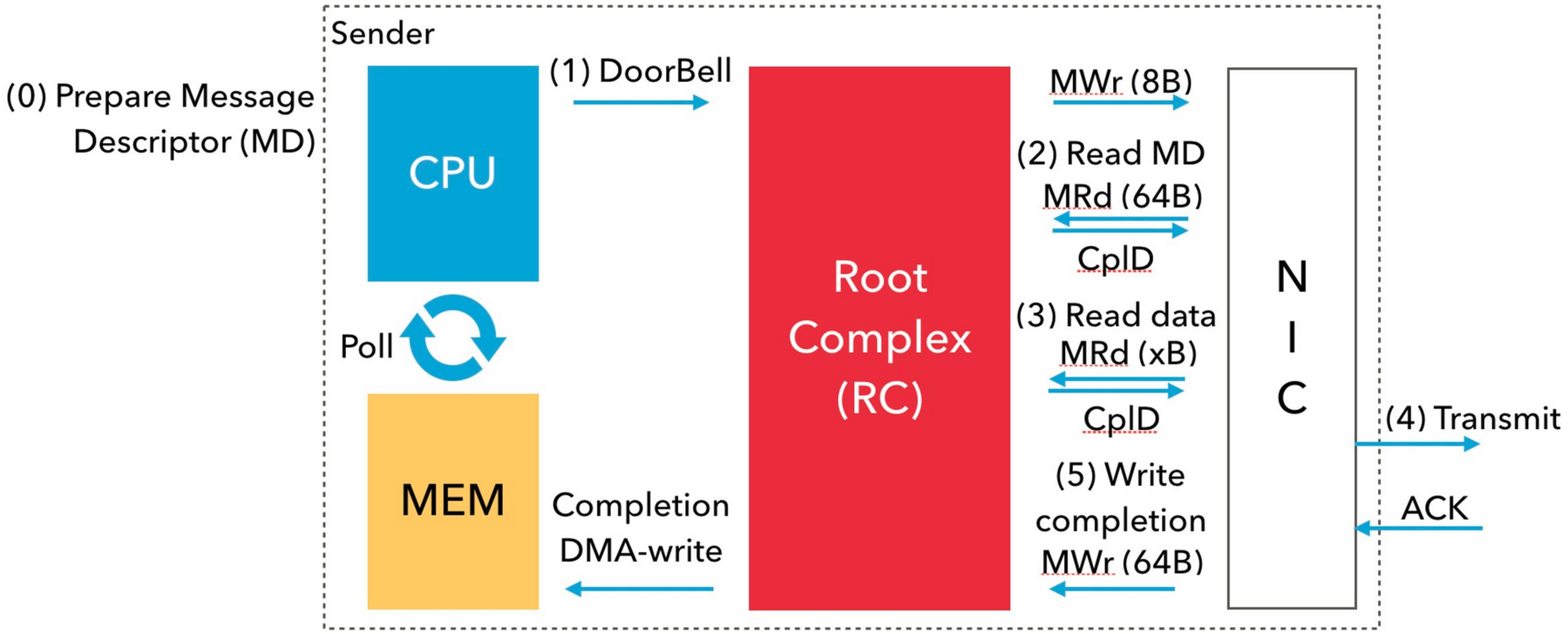
下图描述了数据的实际传输过程:
- (0) 用户向 WQ 提交一个 WQE(也叫 MD);
- (1) 用户态网络驱动通过 MMIO 写入 8 字节通知网卡有消息需要发送。这个机制叫做 DoorBell. PCIe RC (Root Complex) 通过 MWr 事务执行一次 DoorBell - 其实就是通过 MMIO 写 PCIe 设备上一个内存映射的寄存器。
- (2) 网卡通过 DMA read 读取相关信息描述;
- (3) 网卡通过 DMA read 读取待传输的数据;
- (4) 网卡发送数据到目标节点,并从目标网卡获得 Ack;
- (5) 网卡收到 Ack 后通过 DMA write 向 CQ 写入一个 CQE.
也就是说,每发送一次数据,就会有如下开销:1x MMIO, 2x DMA read, 1x DMA write. 在 ThunderX2 机器上,一次 DMA 读取来回在 PCIe 上的开销大约需要 125 纳秒,延迟开销非常昂贵。
相关优化 🔗
- 批量提交,大大降低 DoorBell 次数;
- 内嵌数据,这样一次 DMA read 就可以 - 在 CX-5 上测了一下,前提是数据不超过 60 字节。5
- 批量 CQE,避免每次完成一个 WQE 就写入一个 CQE;
- Mellanox 有个 BlueFrame 技术,可以消除第一个 DMA read - 这种方式下不能使用批量提交。
#2、#4 适合处理非常小的消息;#1、#3 和业务目标相关。
ATC'16 有一篇论文 Design Guidelines for High Performance RDMA Systems 描述了更多相关优化,值得一读。