一起读论文:Parallel All The Time, 2019。该论文有一个改进版本,发表在 IEEE TPDS 2020 的九月刊。标题也有所更改,强调充分利用并发,去掉了“All The Time”。
背景 🔗
之前在上海市计算机学会存储专委会的公众号里, 看到一篇来自华东师范大学的石亮教授(存储专委会主任)的报告,题为“新一代闪存存储系统并行优化技术研究”。

其中,闪存存储系统的并行优化设计被分为三个方向:
- 基于闪存访问冲突最小化的并行优化设计
- 基于芯片空闲时间的垃圾回收导致访问冲突优化策略
- 基于闪存系统并行性最大化的性能优化设计
这里要读的论文 Parallel All the Time 属于第三种,石亮教授是该论文的第二作者。第一作者是厦门大学的高聪明副教授。看论文记录,两位合作已久。
问题描述 🔗
一块 SSD 驱动器内建有如下并发单元:channel, chip, die 以及 plane. 论文认为,作为最下级并发级别 - plane 级并发由于限制最多1,利用率也相当低。利用率低的两个主要原因是主机写和GC. 论文的核心内容就是讨论一种 die 内数据并发优化框架 – 它保证 IO 始终满足 plane 级并发。
SSD 的并发性 🔗
SSD 有四级并发,可以用如下表格来描述:2
| 并发级别 | 名称 | 行为描述 |
|---|---|---|
| Channel | channel striping | 完全并发 |
| Package (LUN) | way pipelining | 通道内串行, 独立的 I/O 请求流水化 |
| Die (chip) | die interleaving | 同上,die 间执行 interleaving command, 数据和命令串行执行 |
| Plane | plane sharing | 执行 multi-plane command, 需要满足前提1 |
Channel 和 chip 级并发无需应用程序干预。Die 和 plane 级并发需要使用相关高级指令。
interleaving command用来提交同 chip 下不同 die 的并发指令;multi-plane command用来提交同 die 下不同 plane 的并发指令 – 限制条件如前所述。通常,一个 die 下会有 2 个或4 个 plane. 在 4 个 plane 的情况下,可以 0&1、2&3 分别执行 multi-plane command. 如果满足条件, 也可以 4 个 plane 一起并发执行。3
interleaving 是一种流水线方式。总线是共享的,加载数据必须串行。数据加载完成后,写入(NAND 术语里叫 programming)操作和下一个加载可以并发执行。一图胜千言。4
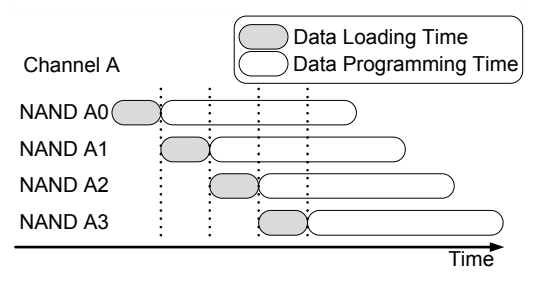
multi-plane command 其实也是一种 die 内的 interleaving. 参考镁光的描述:5
A MULTIPLANE PAGEPROGRAM operation requires the following two steps:
- Serially load up to two pages of data (4224 bytes) into the data buffer.
- Parallel programming of both pages starts after the issue of the Page Confirm command.
问题分类 🔗
论文主要讨论两类问题:如何让写操作和 GC 充分利用 multi-plane 并发。
问题描述 - 主机写 🔗
论文把写入(没有讨论读是因为写入更耗时,且对总体性能影响更大)分为四类:
- Single Write - IO 只写一个 plane;
- 不同类型的操作写入多个 plane;
- Unaligned Write - 都是写,但是目标 plane 里的物理 page offset 不同;
- Parallel Writes - 都是写,in-plane page offset 也相同,能并发。
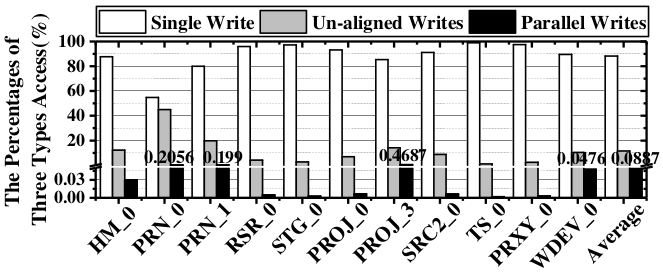
按照以上分类,论文列举了写操作的占比如下图。6看起来 Single Write 居多。
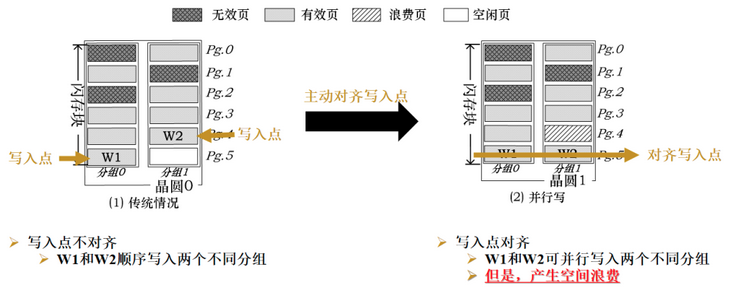
下图,“写入点” 是 in-plane page offset; “分组” 是 plane. 图中描述了一个简单模型:2 个 plane, 每个 plane 里只有一个 block, 每个 block 里有 6 个物理页。一个简单的算法是对写入进行对齐,图里 W1 和 W2 不对齐。如果把 W2 的目标地址和 W1 对齐(刚好是空白页),则会浪费一个页面。这种实现不满足实际需求。
问题描述 - 垃圾回收 🔗
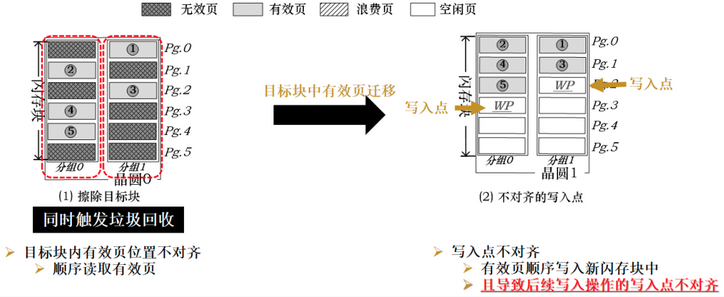
Die 内某 plane 激活 GC 的情况下,GC 完成之前其他 plane 的数据也无法被访问。鉴于此,Shahidi 等人提议同时执行 GC, 以摊薄时间开销。其 ParaGC 算法如下:
- 先选择某个 plane 下包含最多无效页的 block A;
- 如果该 block 对应的 paired-block B 在另一个 plane 下有足够的无效页, 则 A 和 B 可以同时 GC. 否则 A 和 B 需要串行回收。
由于 A 和 B 中包含的有效页面数量可能不等,则容易产生 Unaligned Writes. 同理,如果 A 和 B 串行回收,更容易产生非对齐写。
解决方案 🔗
基于以上分析,论文认为,必须从一开始写时就得考虑面向 multi-plane.
To maximize plane level parallelism, the access addresses of writes on all planes in the same die should be aligned at all time.
针对写入和GC,论文提出一下解决方案:
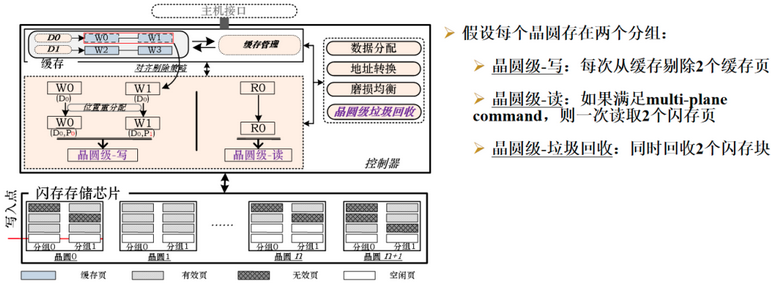
- 利用 SSD buffer 对写入数据做整形,从而保证写入符合 Parallel Writes 的要求。
- 数据的分配算法采用TBM – 在 die 内的 plane 之间进行 round-robin.
基于 buffer 整形的 Die-Write 🔗
维护一个 die 队列,假设有 4 个 die, 每个 die 里面有 2 个 plane, 如下图。
- 每个 die 上维护一个 LRU 链表管理脏页;
- 为了保持 die 的写平衡,对 die 上的写采用 round-robin;
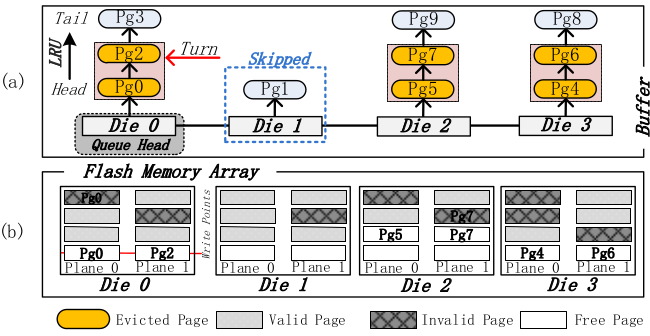
Buffer 的 evict 机制(从 buffer 选取 page 写入到 die)以上图为例:当前 Queue head 在 die0, 先从这里扫描,跳过 die1(没有足够的 dirty page)到 die2、die3,然后分别从 die0, die2, die3 各自淘汰 2 个页面。该方案依赖超级电容等相关设施处理掉电。
假设 die 里面有 N 个 plane, 每次淘汰的页面总是 N 的倍数。
die 上的读无法做类似的处理,因为读取的地址是指定的。
Die 上的 GC 改进 🔗
GC 分为三步:1) 选择待搬迁 block A; 2) 搬运数据到目标 block B; 3) 擦除 block A. 这里的主要开销是第二步搬迁数据,也是改进的重点。
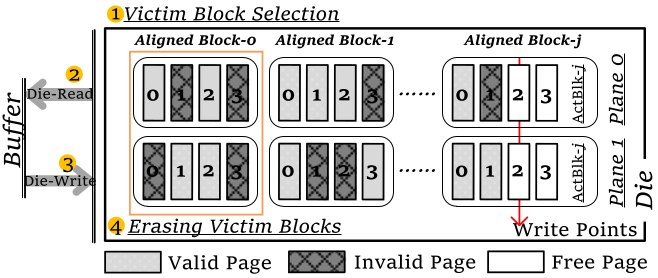
Die-GC 的改进是以 Die-Write 为基础的。考虑到擦除以 block 为粒度,定义aligned block 为具有相同 in-plane 地址的 block. 算法步骤如下:
- 对每组 aligned block 中的有效页面数量求和,数量最少的被牺牲;
- 把选中的一组 aligned block 中的有效页面读取 N 个到 SSD buffer;7
- 触发一次对齐的 Die-Write;
- 重复 #2 直到所有的有效页面都被回写就可以对被牺牲的 block 进行成组擦除了。8
上图描述的是把 aligned block-0 中的数据搬迁到 aligned block-j 的过程。
后记 🔗
Flash plane interleaving 可以显著提高性能(30% ~ 80%),其前提是事先匹配不同目标 plane 下的物理页的地址。如果不幸存在坏块,就很难有用武之地了。9 此外,生产环境还得考虑磨损均衡。理想很丰满,现实很骨感。
一些 SSD 模拟器。相关 NAND SSD 知识也许可以参考上一篇 SSD 101 Plus。
-
4 个 plane 时两两并发有分组,不能 0&2 或 1&3. ↩︎
-
如前,N 是 die 内 plane 的数量。 ↩︎
-
因此对 SSD 的寿命有不利影响。 ↩︎
-
参考 Interleaving, Flash Bus Interfaces, and Flash Memory Speed ↩︎